# Pacotes necessários
library(tidyverse)
library(pracma)
library(lme4)
library(lmerTest)
library(pbkrtest)
library(readxl)
# Importar os dados
dados <- read_excel("Trabalho final Emerson.xlsx", sheet = "Planilha1")Ranking dos tratamentos
Nesta etapa, os dados foram organizados para calcular a AACPD (área abaixo da curva de progresso da doença) por unidade experimental. Em seguida, ajustamos um modelo misto linear considerando o efeito fixo dos tratamentos e os efeitos aleatórios associados à estrutura hierárquica (planta, trifólio, folíolo e avaliador). Por fim, obtivemos as médias ajustadas por tratamento e realizamos o teste de comparação de médias com ajuste de Tukey.
Calcular AACPD por unidade experimental
aacpd_result <- dados %>%
group_by(Tratamento, Planta, Trifolio, Foliolo, Avaliador) %>%
summarise(
AACPD = trapz(Dia, Severidade),
.groups = "drop"
)Ajustar modelo misto com efeito fixo de Tratamento e estrutura hierárquica de efeitos aleatórios
modelo_completo <- lmer(
AACPD ~ Tratamento + (1 | Planta/Trifolio/Foliolo/Avaliador),
data = aacpd_result,
REML = FALSE # necessário para comparação de modelos
)
# 3. Ajustar modelo misto (se ainda não tiver feito)
modelo_completo <- lmer(
AACPD ~ Tratamento + (1 | Planta/Trifolio/Foliolo/Avaliador),
data = aacpd_result,
REML = TRUE # pode voltar a usar REML aqui para melhores estimativas
)Em seguida, usamos o pacote emmeans para extrair as médias ajustadas por tratamento com base no modelo, e fizemos comparações múltiplas com correção de Tukey. Também ranqueamos os tratamentos com base nas diferenças significativas entre eles.
library(emmeans)
medias <- emmeans(modelo_completo, ~ Tratamento)
comparacoes <- pairs(medias, adjust = "tukey")
print(comparacoes) contrast estimate SE df t.ratio p.value
CONTROLE - Isolado 1 111.18 32.4 590 3.429 0.0269
CONTROLE - Isolado 2 114.20 32.4 590 3.522 0.0198
CONTROLE - Isolado 3 58.06 32.4 590 1.791 0.7854
CONTROLE - Isolado 4 193.64 32.4 590 5.972 <.0001
CONTROLE - Isolado 5 67.57 32.4 590 2.084 0.5893
CONTROLE - Isolado 6 -87.03 32.4 590 -2.684 0.2095
CONTROLE - Isolado 7 29.01 32.4 590 0.895 0.9983
CONTROLE - Produto 1 247.87 32.4 590 7.644 <.0001
CONTROLE - Produto 2 82.39 32.4 590 2.541 0.2830
CONTROLE - Produto 3 170.93 32.4 590 5.272 <.0001
Isolado 1 - Isolado 2 3.02 32.4 590 0.093 1.0000
Isolado 1 - Isolado 3 -53.12 32.4 590 -1.638 0.8653
Isolado 1 - Isolado 4 82.46 32.4 590 2.543 0.2818
Isolado 1 - Isolado 5 -43.61 32.4 590 -1.345 0.9604
Isolado 1 - Isolado 6 -198.22 32.4 590 -6.113 <.0001
Isolado 1 - Isolado 7 -82.17 32.4 590 -2.534 0.2868
Isolado 1 - Produto 1 136.69 32.4 590 4.216 0.0014
Isolado 1 - Produto 2 -28.79 32.4 590 -0.888 0.9984
Isolado 1 - Produto 3 59.75 32.4 590 1.843 0.7540
Isolado 2 - Isolado 3 -56.14 32.4 590 -1.731 0.8189
Isolado 2 - Isolado 4 79.44 32.4 590 2.450 0.3367
Isolado 2 - Isolado 5 -46.63 32.4 590 -1.438 0.9383
Isolado 2 - Isolado 6 -201.24 32.4 590 -6.206 <.0001
Isolado 2 - Isolado 7 -85.19 32.4 590 -2.627 0.2370
Isolado 2 - Produto 1 133.66 32.4 590 4.122 0.0021
Isolado 2 - Produto 2 -31.81 32.4 590 -0.981 0.9964
Isolado 2 - Produto 3 56.73 32.4 590 1.749 0.8090
Isolado 3 - Isolado 4 135.58 32.4 590 4.181 0.0017
Isolado 3 - Isolado 5 9.51 32.4 590 0.293 1.0000
Isolado 3 - Isolado 6 -145.10 32.4 590 -4.475 0.0005
Isolado 3 - Isolado 7 -29.05 32.4 590 -0.896 0.9983
Isolado 3 - Produto 1 189.80 32.4 590 5.854 <.0001
Isolado 3 - Produto 2 24.32 32.4 590 0.750 0.9996
Isolado 3 - Produto 3 112.86 32.4 590 3.481 0.0227
Isolado 4 - Isolado 5 -126.07 32.4 590 -3.888 0.0053
Isolado 4 - Isolado 6 -280.68 32.4 590 -8.656 <.0001
Isolado 4 - Isolado 7 -164.63 32.4 590 -5.077 <.0001
Isolado 4 - Produto 1 54.22 32.4 590 1.672 0.8492
Isolado 4 - Produto 2 -111.25 32.4 590 -3.431 0.0267
Isolado 4 - Produto 3 -22.71 32.4 590 -0.701 0.9998
Isolado 5 - Isolado 6 -154.60 32.4 590 -4.768 0.0001
Isolado 5 - Isolado 7 -38.56 32.4 590 -1.189 0.9835
Isolado 5 - Produto 1 180.29 32.4 590 5.560 <.0001
Isolado 5 - Produto 2 14.82 32.4 590 0.457 1.0000
Isolado 5 - Produto 3 103.36 32.4 590 3.188 0.0569
Isolado 6 - Isolado 7 116.05 32.4 590 3.579 0.0163
Isolado 6 - Produto 1 334.90 32.4 590 10.329 <.0001
Isolado 6 - Produto 2 169.43 32.4 590 5.225 <.0001
Isolado 6 - Produto 3 257.96 32.4 590 7.956 <.0001
Isolado 7 - Produto 1 218.85 32.4 590 6.750 <.0001
Isolado 7 - Produto 2 53.38 32.4 590 1.646 0.8616
Isolado 7 - Produto 3 141.92 32.4 590 4.377 0.0007
Produto 1 - Produto 2 -165.47 32.4 590 -5.103 <.0001
Produto 1 - Produto 3 -76.94 32.4 590 -2.373 0.3861
Produto 2 - Produto 3 88.54 32.4 590 2.731 0.1888
Degrees-of-freedom method: kenward-roger
P value adjustment: tukey method for comparing a family of 11 estimates # Letras para o ranking
ranking <- multcomp::cld(medias, Letters = letters)
print(ranking) Tratamento emmean SE df lower.CL upper.CL .group
Produto 1 123 33.9 11.6 48.8 197 a
Isolado 4 177 33.9 11.6 103.0 251 ab
Produto 3 200 33.9 11.6 125.7 274 abc
Isolado 2 257 33.9 11.6 182.4 331 bcd
Isolado 1 260 33.9 11.6 185.5 334 bcd
Produto 2 288 33.9 11.6 214.3 363 cde
Isolado 5 303 33.9 11.6 229.1 377 cde
Isolado 3 313 33.9 11.6 238.6 387 de
Isolado 7 342 33.9 11.6 267.6 416 de
CONTROLE 371 33.9 11.6 296.7 445 ef
Isolado 6 458 33.9 11.6 383.7 532 f
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95
P value adjustment: tukey method for comparing a family of 11 estimates
significance level used: alpha = 0.05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same. Gráfico comparando os tratamentos
A seguir, geramos um gráfico de barras com as médias ajustadas por tratamento, incluindo os intervalos de confiança e as letras de significância estatística. Os nomes dos tratamentos foram padronizados e a ordem foi ajustada de acordo com a severidade média.
library(emmeans)
library(multcomp)
library(ggplot2)
library(dplyr)
library(stringr)
# 1. Obter médias ajustadas do modelo
medias <- emmeans(modelo_completo, ~ Tratamento)
# 2. Comparações com Tukey + letras de significância
letras <- cld(medias, Letters = letters, adjust = "tukey")
# 3. Remover espaços das letras
letras$.group <- gsub(" ", "", letras$.group)
# 4. Renomear tratamentos corretamente
letras$Tratamento <- letras$Tratamento %>%
str_replace("(?i)isola[dt]o\\s*", "Iso. ") %>%
str_replace("(?i)produto\\s*", "Prod. ") %>%
str_replace("(?i)controle", "Cont.")
# 5. Ordenar por AACPD (emmean) e fixar ordem como fator
letras <- letras %>%
arrange(emmean) %>%
mutate(Tratamento = factor(Tratamento, levels = Tratamento))
# 6. Plot com nomes e ordem corrigidos
ggplot(letras, aes(x = Tratamento, y = emmean)) +
geom_col(fill = "#4682B4", width = 0.7) +
geom_errorbar(aes(ymin = lower.CL, ymax = upper.CL), width = 0.2) +
geom_text(aes(label = .group), vjust = -0.5, size = 5) +
labs(
title = "AACPD ajustado por tratamento",
y = "AACPD (área abaixo da curva)",
x = "Tratamento"
) +
theme_minimal(base_size = 14) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))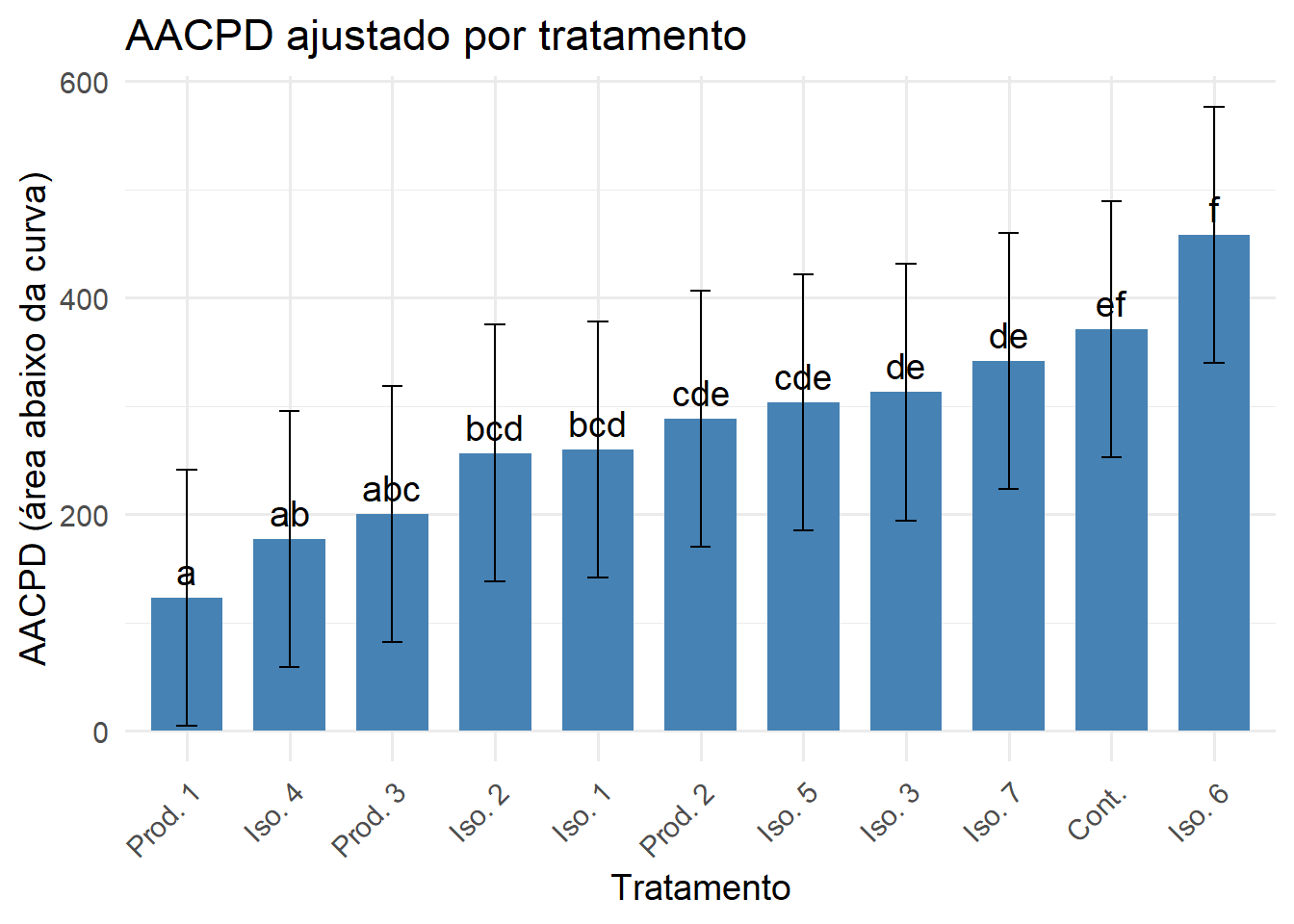
Modelo Generalizado - TESTE DE AJUSTE VIA K-S
Nesta etapa, testamos a distribuição dos valores de AACPD para avaliar a adequação de diferentes famílias de distribuições (normal, gamma, log-normal e beta), usando o teste de Kolmogorov–Smirnov (K-S). Isso nos ajuda a escolher a melhor família para ajuste de modelos generalizados.
library(MASS) # Para fitdistr
library(stats)
# Vetor de resposta
x <- aacpd_result$AACPD
# 1. Normal
ks.test(x, "pnorm", mean = mean(x), sd = sd(x))
Asymptotic one-sample Kolmogorov-Smirnov test
data: x
D = 0.12414, p-value = 2.924e-09
alternative hypothesis: two-sided# 2. Gamma
gamma_fit <- fitdistr(x, "gamma")
ks.test(x, "pgamma", shape = gamma_fit$estimate["shape"], rate = gamma_fit$estimate["rate"])
Asymptotic one-sample Kolmogorov-Smirnov test
data: x
D = 0.032826, p-value = 0.4755
alternative hypothesis: two-sided# 3. Log-Normal
ks.test(x, "plnorm", meanlog = mean(log(x)), sdlog = sd(log(x)))
Asymptotic one-sample Kolmogorov-Smirnov test
data: x
D = 0.050365, p-value = 0.07028
alternative hypothesis: two-sided# 4. Beta — somente se seus dados estiverem entre 0 e 1
# Primeiro normaliza se necessário
x_beta <- (x - min(x) + 0.001) / (max(x) - min(x) + 0.002) # para garantir que caia entre (0,1)
beta_fit <- fitdistr(x_beta, dbeta, start = list(shape1 = 1, shape2 = 1))
ks.test(x_beta, "pbeta", shape1 = beta_fit$estimate["shape1"], shape2 = beta_fit$estimate["shape2"])
Asymptotic one-sample Kolmogorov-Smirnov test
data: x_beta
D = 0.087589, p-value = 7.998e-05
alternative hypothesis: two-sidedModelo Generalizado
Com base nos testes anteriores, ajustamos um modelo misto generalizado (GLMM) com distribuição Gamma e link log, apropriado para variáveis contínuas, positivas e assimétricas como a AACPD. Realizamos diagnóstico dos resíduos e extraímos as médias ajustadas com as respectivas comparações.
# Pacotes
library(DHARMa)
library(readxl)
library(pracma)
library(emmeans)
library(multcompView)
library(multcomp)
library(stringr)
# 1. Carregar os dados
dados <- read_excel("Trabalho final Emerson.xlsx", sheet = "Planilha1")
# 2. Calcular AACPD por unidade experimental
aacpd_result <- dados %>%
arrange(Planta, Trifolio, Foliolo, Avaliador, Tratamento, Dia) %>%
group_by(Planta, Trifolio, Foliolo, Avaliador, Tratamento) %>%
summarise(
AACPD = trapz(Dia, Severidade),
.groups = "drop"
)
# 3. Ajustar valores zero (GLMM Gamma não aceita zeros)
aacpd_result <- aacpd_result %>%
mutate(AACPD_adj = AACPD + 0.01)
# 4. Modelo misto com distribuição Gamma
modelo_glmm <- glmer(
AACPD_adj ~ Tratamento + (1 | Planta/Trifolio/Foliolo/Avaliador),
data = aacpd_result,
family = Gamma(link = "log")
)
# 5. Diagnóstico
summary(modelo_glmm)Generalized linear mixed model fit by maximum likelihood (Laplace
Approximation) [glmerMod]
Family: Gamma ( log )
Formula: AACPD_adj ~ Tratamento + (1 | Planta/Trifolio/Foliolo/Avaliador)
Data: aacpd_result
AIC BIC logLik -2*log(L) df.resid
8324.8 8396.7 -4146.4 8292.8 644
Scaled residuals:
Min 1Q Median 3Q Max
-1.4414 -0.6120 -0.2084 0.3580 5.1689
Random effects:
Groups Name Variance Std.Dev.
Avaliador:Foliolo:Trifolio:Planta (Intercept) 8.026e-10 2.833e-05
Foliolo:Trifolio:Planta (Intercept) 8.767e-03 9.363e-02
Trifolio:Planta (Intercept) 3.978e-02 1.994e-01
Planta (Intercept) 2.345e-10 1.531e-05
Residual 3.591e-01 5.992e-01
Number of obs: 660, groups:
Avaliador:Foliolo:Trifolio:Planta, 60; Foliolo:Trifolio:Planta, 30; Trifolio:Planta, 10; Planta, 5
Fixed effects:
Estimate Std. Error t value Pr(>|z|)
(Intercept) 5.79954 0.12400 46.771 < 2e-16 ***
TratamentoIsolado 1 -0.25062 0.10227 -2.451 0.01426 *
TratamentoIsolado 2 -0.31710 0.10296 -3.080 0.00207 **
TratamentoIsolado 3 -0.11246 0.10163 -1.107 0.26845
TratamentoIsolado 4 -0.66000 0.10310 -6.401 1.54e-10 ***
TratamentoIsolado 5 -0.14775 0.10224 -1.445 0.14842
TratamentoIsolado 6 0.31551 0.10242 3.081 0.00207 **
TratamentoIsolado 7 0.02666 0.10181 0.262 0.79346
TratamentoProduto 1 -1.07535 0.10149 -10.596 < 2e-16 ***
TratamentoProduto 2 -0.18679 0.10126 -1.845 0.06509 .
TratamentoProduto 3 -0.55054 0.10177 -5.410 6.31e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) TrtmI1 TrtmI2 TrtmI3 TrtmI4 TrtmI5 TrtmI6 TrtmI7 TrtmP1
TrtmntIsld1 -0.414
TrtmntIsld2 -0.412 0.509
TrtmntIsld3 -0.410 0.503 0.499
TrtmntIsld4 -0.409 0.507 0.501 0.505
TrtmntIsld5 -0.411 0.504 0.511 0.497 0.490
TrtmntIsld6 -0.409 0.496 0.498 0.496 0.492 0.494
TrtmntIsld7 -0.413 0.508 0.507 0.499 0.503 0.505 0.500
TrtmntPrdt1 -0.402 0.484 0.485 0.485 0.477 0.484 0.495 0.490
TrtmntPrdt2 -0.410 0.500 0.497 0.501 0.491 0.500 0.500 0.500 0.492
TrtmntPrdt3 -0.411 0.505 0.503 0.497 0.493 0.508 0.493 0.505 0.485
TrtmP2
TrtmntIsld1
TrtmntIsld2
TrtmntIsld3
TrtmntIsld4
TrtmntIsld5
TrtmntIsld6
TrtmntIsld7
TrtmntPrdt1
TrtmntPrdt2
TrtmntPrdt3 0.501
optimizer (Nelder_Mead) convergence code: 0 (OK)
boundary (singular) fit: see help('isSingular')res_sim <- simulateResiduals(modelo_glmm)
plot(res_sim)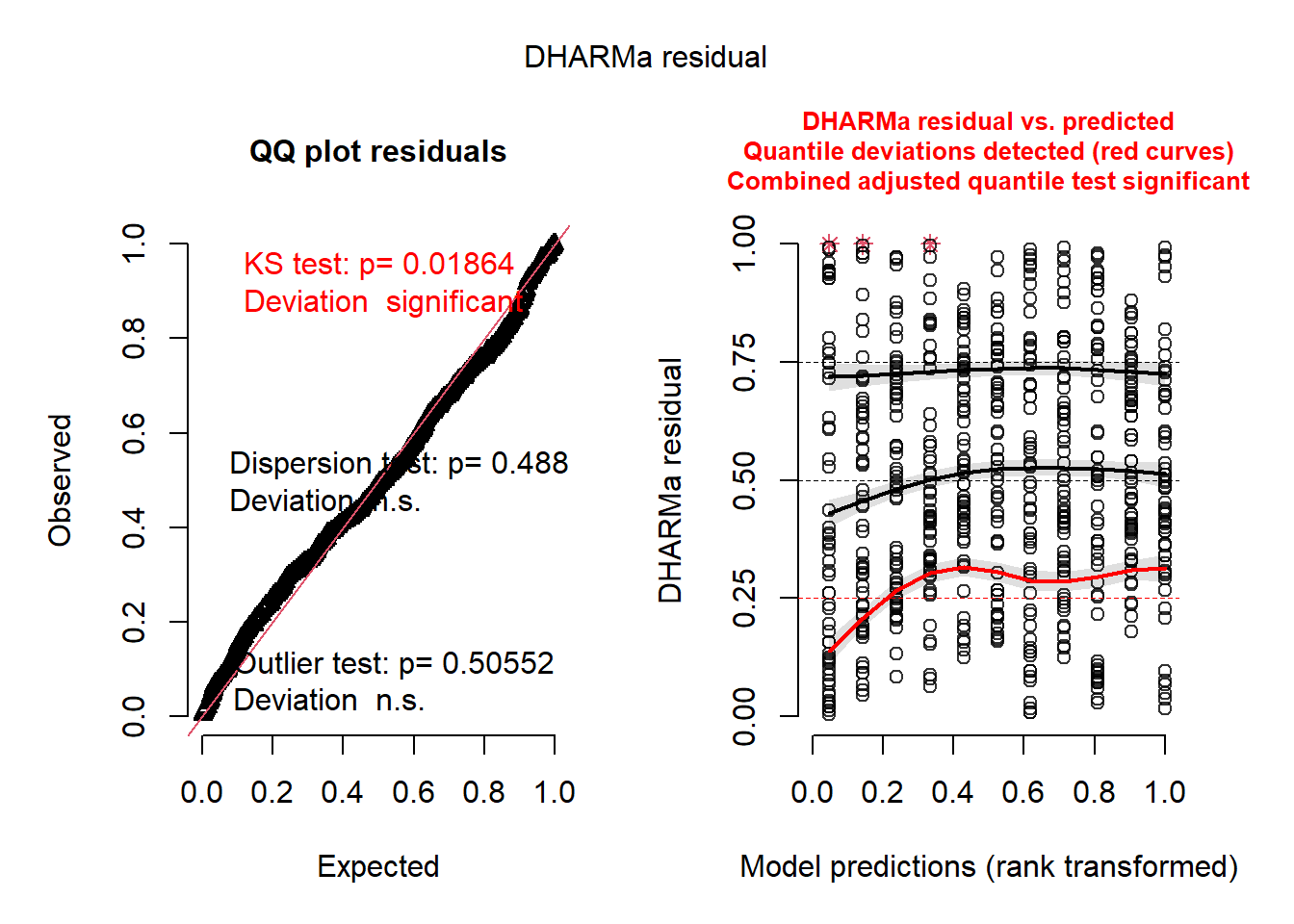
# 6. Médias ajustadas e letras
medias <- emmeans(modelo_glmm, ~ Tratamento, type = "response")
letras <- cld(medias, Letters = letters, adjust = "tukey")
letras$.group <- gsub(" ", "", letras$.group)
# 7. Renomear tratamentos
letras$Tratamento <- letras$Tratamento %>%
str_replace("(?i)isola[dt]o\\s*", "Iso. ") %>%
str_replace("(?i)produto\\s*", "Prod. ") %>%
str_replace("(?i)controle", "Cont.")
# 8. Organizar para gráfico
letras_df <- letras[, c("Tratamento", "response", "SE", ".group")]
# Reordena com base nos valores médios
ordem <- letras_df$Tratamento[order(letras_df$response)]
letras_df$Tratamento <- factor(letras_df$Tratamento, levels = ordem)
# 9. Gráfico
ggplot(letras_df, aes(x = Tratamento, y = response)) +
geom_col(fill = "#66c2a5", width = 0.7) +
geom_errorbar(aes(ymin = response - SE, ymax = response + SE), width = 0.2) +
geom_text(aes(label = .group), vjust = -0.5, fontface = "bold", size = 5) +
labs(
title = "AACPD dos tratamentos",
x = "Tratamentos",
y = "AACPD"
) +
theme_minimal(base_size = 14) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))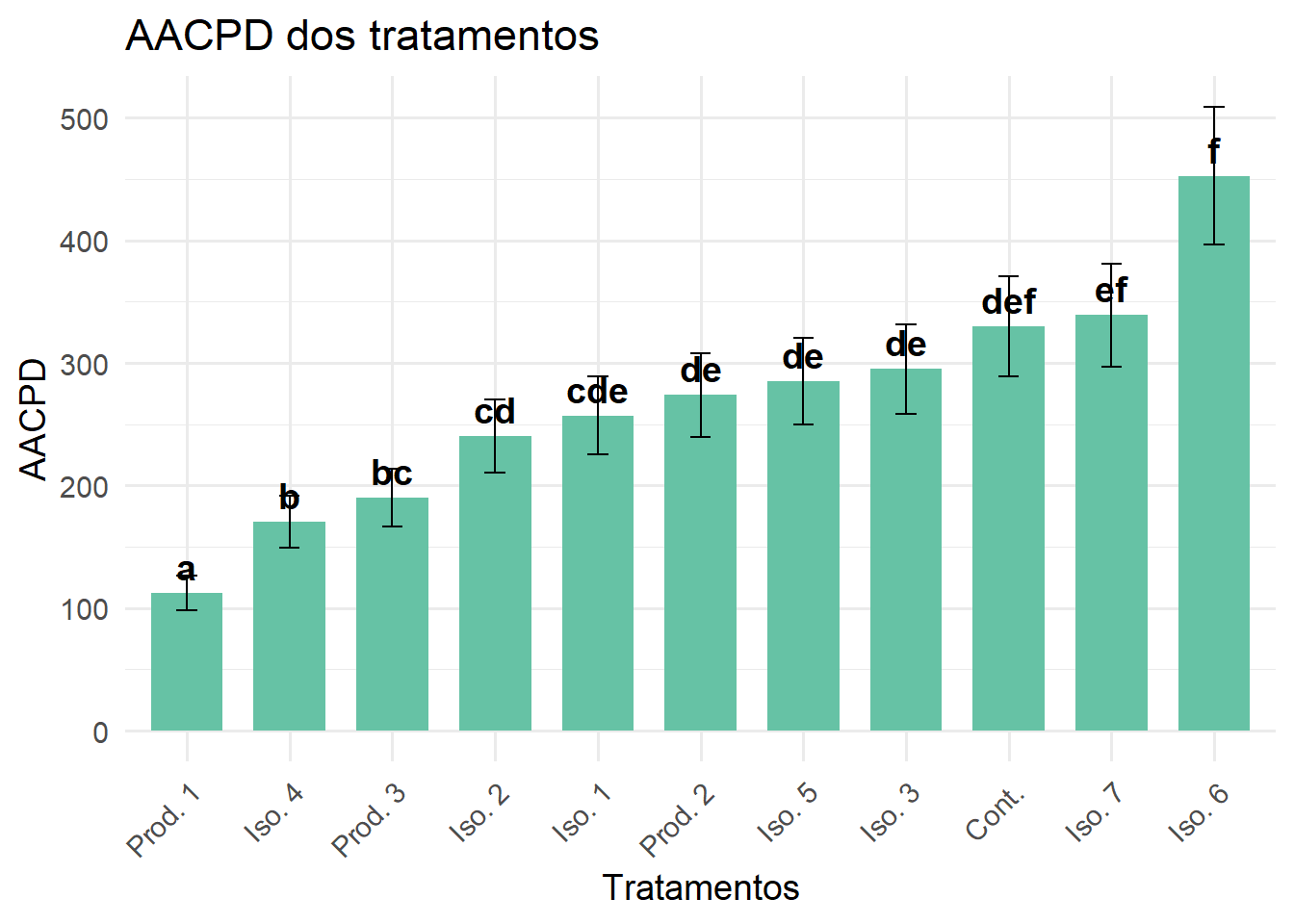
AACPD em 28 dias
Para avaliar o desempenho dos tratamentos na fase inicial da epidemia, filtramos os dados até 28 dias após a inoculação. Repetimos a análise com GLMM Gamma e geramos gráfico com médias ajustadas e significância estatística.
# -----------------------------
# 📦 Pacotes
# -----------------------------
library(DHARMa)
library(readxl)
library(tidyverse)
library(pracma)
library(lme4)
library(emmeans)
library(multcompView)
library(multcomp)
library(stringr)
# -----------------------------
# 📥 1. Carregar os dados
# -----------------------------
dados <- read_excel("Trabalho final Emerson.xlsx", sheet = "Planilha1")
# -----------------------------
# 🧹 2. Filtrar até o dia 28
# -----------------------------
dados_filtrados_28 <- dados %>%
filter(Dia <= 28)
# -----------------------------
# 📊 3. Calcular AACPD por unidade experimental
# -----------------------------
aacpd_result_28 <- dados_filtrados_28 %>%
arrange(Planta, Trifolio, Foliolo, Avaliador, Tratamento, Dia) %>%
group_by(Planta, Trifolio, Foliolo, Avaliador, Tratamento) %>%
summarise(
AACPD = trapz(Dia, Severidade),
.groups = "drop"
)
# -----------------------------
# ⚠️ 4. Ajustar valores zero (GLMM Gamma não aceita zeros)
# -----------------------------
aacpd_result_28 <- aacpd_result_28 %>%
mutate(AACPD_adj_28 = AACPD + 0.01)
# -----------------------------
# 🏗️ 5. Modelo misto com distribuição Gamma
# -----------------------------
modelo_glmm_28 <- glmer(
AACPD_adj_28 ~ Tratamento + (1 | Planta/Trifolio/Foliolo/Avaliador),
data = aacpd_result_28,
family = Gamma(link = "log")
)
# -----------------------------
# 🧪 6. Diagnóstico de resíduos
# -----------------------------
summary(modelo_glmm_28)Generalized linear mixed model fit by maximum likelihood (Laplace
Approximation) [glmerMod]
Family: Gamma ( log )
Formula: AACPD_adj_28 ~ Tratamento + (1 | Planta/Trifolio/Foliolo/Avaliador)
Data: aacpd_result_28
AIC BIC logLik -2*log(L) df.resid
5875.8 5947.6 -2921.9 5843.8 644
Scaled residuals:
Min 1Q Median 3Q Max
-1.0400 -0.6989 -0.2830 0.3818 6.1772
Random effects:
Groups Name Variance Std.Dev.
Avaliador:Foliolo:Trifolio:Planta (Intercept) 1.587e-10 1.260e-05
Foliolo:Trifolio:Planta (Intercept) 7.515e-10 2.741e-05
Trifolio:Planta (Intercept) 1.659e-01 4.073e-01
Planta (Intercept) 0.000e+00 0.000e+00
Residual 9.235e-01 9.610e-01
Number of obs: 660, groups:
Avaliador:Foliolo:Trifolio:Planta, 60; Foliolo:Trifolio:Planta, 30; Trifolio:Planta, 10; Planta, 5
Fixed effects:
Estimate Std. Error t value Pr(>|z|)
(Intercept) 3.54429 0.18076 19.607 < 2e-16 ***
TratamentoIsolado 1 -0.99482 0.17116 -5.812 6.16e-09 ***
TratamentoIsolado 2 -0.06320 0.17974 -0.352 0.725139
TratamentoIsolado 3 0.09244 0.17461 0.529 0.596518
TratamentoIsolado 4 -0.04231 0.17683 -0.239 0.810896
TratamentoIsolado 5 0.32835 0.17554 1.871 0.061413 .
TratamentoIsolado 6 1.03009 0.17319 5.948 2.72e-09 ***
TratamentoIsolado 7 -0.53633 0.17184 -3.121 0.001801 **
TratamentoProduto 1 -0.54004 0.17409 -3.102 0.001922 **
TratamentoProduto 2 -0.26609 0.17107 -1.555 0.119831
TratamentoProduto 3 -0.60673 0.17284 -3.510 0.000447 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) TrtmI1 TrtmI2 TrtmI3 TrtmI4 TrtmI5 TrtmI6 TrtmI7 TrtmP1
TrtmntIsld1 -0.467
TrtmntIsld2 -0.473 0.468
TrtmntIsld3 -0.471 0.484 0.500
TrtmntIsld4 -0.454 0.487 0.474 0.468
TrtmntIsld5 -0.473 0.481 0.512 0.503 0.455
TrtmntIsld6 -0.469 0.476 0.486 0.477 0.462 0.480
TrtmntIsld7 -0.472 0.493 0.483 0.496 0.460 0.506 0.483
TrtmntPrdt1 -0.460 0.482 0.458 0.464 0.430 0.465 0.495 0.488
TrtmntPrdt2 -0.475 0.492 0.493 0.495 0.485 0.490 0.502 0.491 0.484
TrtmntPrdt3 -0.475 0.484 0.501 0.495 0.456 0.505 0.494 0.504 0.496
TrtmP2
TrtmntIsld1
TrtmntIsld2
TrtmntIsld3
TrtmntIsld4
TrtmntIsld5
TrtmntIsld6
TrtmntIsld7
TrtmntPrdt1
TrtmntPrdt2
TrtmntPrdt3 0.493
optimizer (Nelder_Mead) convergence code: 0 (OK)
boundary (singular) fit: see help('isSingular')res_sim_28 <- simulateResiduals(modelo_glmm_28)
plot(res_sim_28)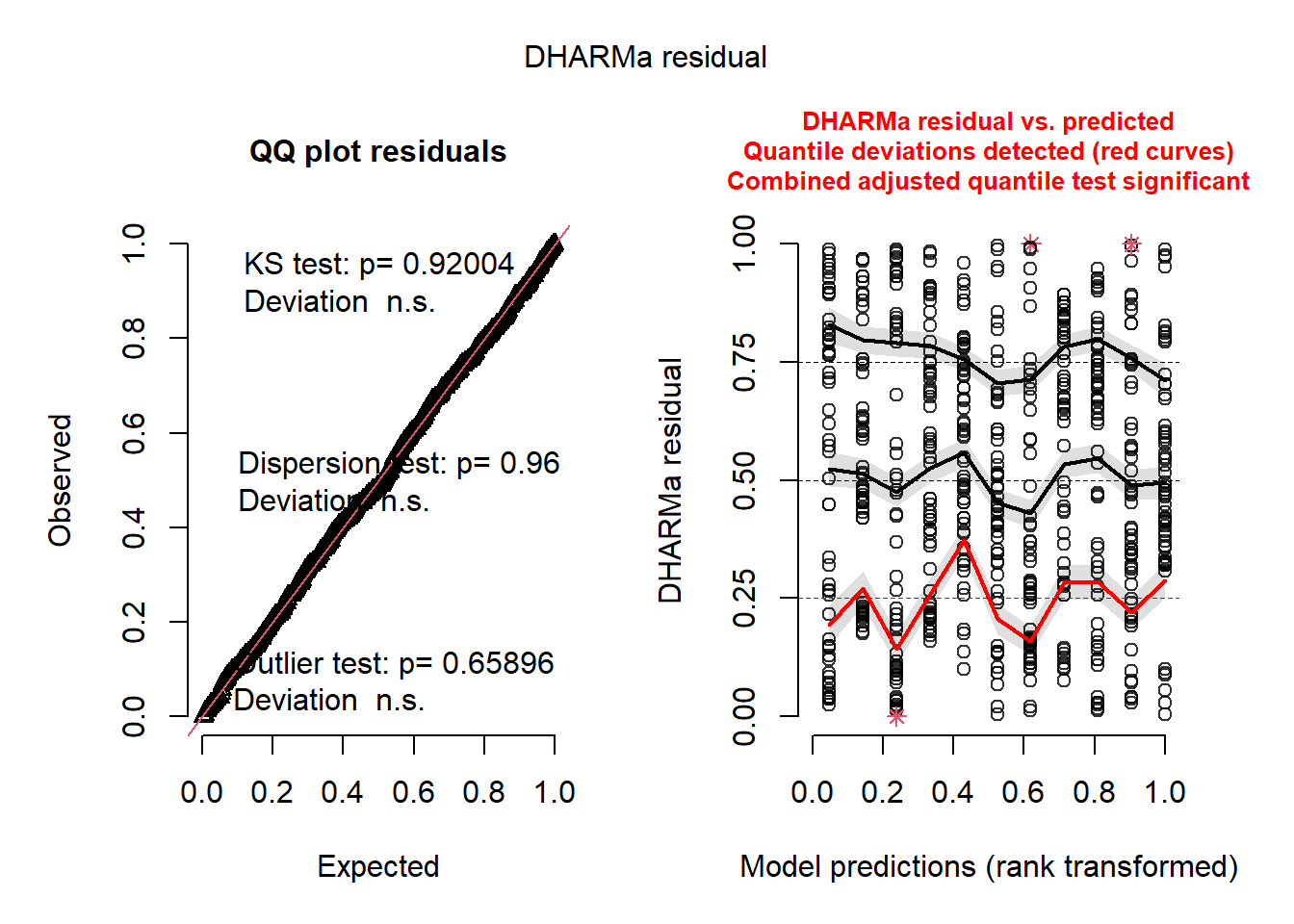
# -----------------------------
# 📊 7. Médias ajustadas e letras de significância
# -----------------------------
medias_28 <- emmeans(modelo_glmm_28, ~ Tratamento, type = "response")
letras_28 <- cld(medias_28, Letters = letters, adjust = "tukey")
letras_28$.group <- gsub(" ", "", letras_28$.group)
# Renomear tratamentos para gráfico
letras_28$Tratamento <- letras_28$Tratamento %>%
str_replace("(?i)isola[dt]o\\s*", "Iso. ") %>%
str_replace("(?i)produto\\s*", "Prod. ") %>%
str_replace("(?i)controle", "Cont.")
# -----------------------------
# 📦 8. Organizar para gráfico
# -----------------------------
letras_df_28 <- letras_28[, c("Tratamento", "response", "SE", ".group")]
# Reordenar fatores para o gráfico
ordem_28 <- letras_df_28$Tratamento[order(letras_df_28$response)]
letras_df_28$Tratamento <- factor(letras_df_28$Tratamento, levels = ordem_28)
# -----------------------------
# 🎨 9. Gráfico final
# -----------------------------
ggplot(letras_df_28, aes(x = Tratamento, y = response)) +
geom_col(fill = "#CC5500", width = 0.7) +
geom_errorbar(aes(ymin = response - SE, ymax = response + SE), width = 0.2) +
geom_text(aes(label = .group), vjust = -0.5, fontface = "bold", size = 5) +
labs(
title = "AACPD dos tratamentos (até 28 dias)",
x = "Tratamentos",
y = "AACPD"
) +
theme_minimal(base_size = 14) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))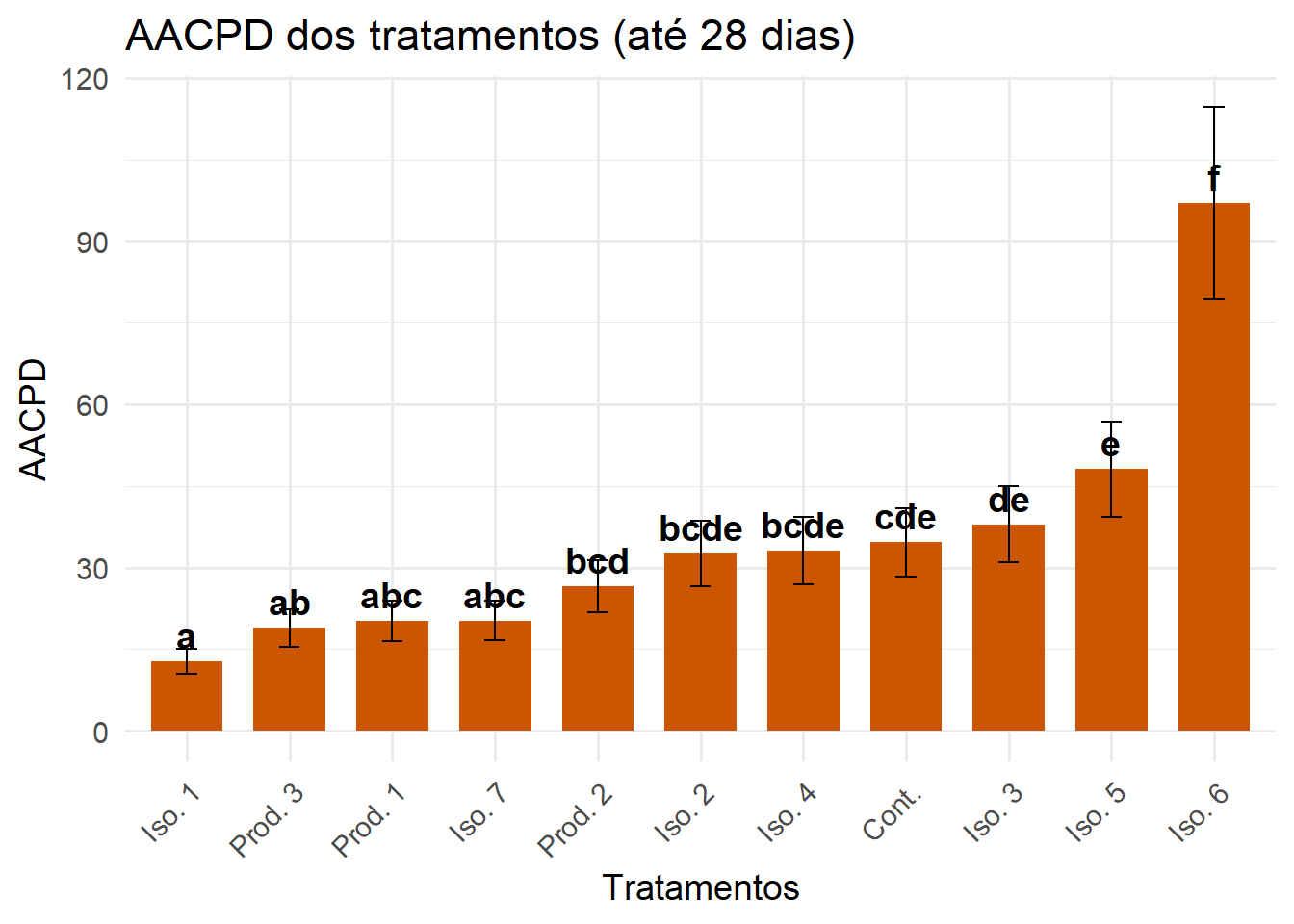
AACPD 35 dias
Da mesma forma, realizamos uma análise restrita aos primeiros 35 dias, refletindo a progressão intermediária da doença. As análises seguem os mesmos procedimentos da etapa anterior.
# -----------------------------
# 📦 Pacotes
# -----------------------------
library(DHARMa)
library(readxl)
library(tidyverse)
library(pracma)
library(lme4)
library(emmeans)
library(multcompView)
library(multcomp)
library(stringr)
# -----------------------------
# 📥 1. Carregar os dados
# -----------------------------
dados <- read_excel("Trabalho final Emerson.xlsx", sheet = "Planilha1")
# -----------------------------
# 🧹 2. Filtrar até o dia 35
# -----------------------------
dados_filtrados_35 <- dados %>%
filter(Dia <= 35)
# -----------------------------
# 📊 3. Calcular AACPD por unidade experimental
# -----------------------------
aacpd_result_35 <- dados_filtrados_35 %>%
arrange(Planta, Trifolio, Foliolo, Avaliador, Tratamento, Dia) %>%
group_by(Planta, Trifolio, Foliolo, Avaliador, Tratamento) %>%
summarise(
AACPD = trapz(Dia, Severidade),
.groups = "drop"
)
# -----------------------------
# ⚠️ 4. Ajustar valores zero (GLMM Gamma não aceita zeros)
# -----------------------------
aacpd_result_35 <- aacpd_result_35 %>%
mutate(AACPD_adj_35 = AACPD + 0.01)
# -----------------------------
# 🏗️ 5. Modelo misto com distribuição Gamma
# -----------------------------
modelo_glmm_35 <- glmer(
AACPD_adj_35 ~ Tratamento + (1 | Planta/Trifolio/Foliolo/Avaliador),
data = aacpd_result_35,
family = Gamma(link = "log")
)
# -----------------------------
# 🧪 6. Diagnóstico de resíduos
# -----------------------------
summary(modelo_glmm_35)Generalized linear mixed model fit by maximum likelihood (Laplace
Approximation) [glmerMod]
Family: Gamma ( log )
Formula: AACPD_adj_35 ~ Tratamento + (1 | Planta/Trifolio/Foliolo/Avaliador)
Data: aacpd_result_35
AIC BIC logLik -2*log(L) df.resid
6879.4 6951.3 -3423.7 6847.4 644
Scaled residuals:
Min 1Q Median 3Q Max
-1.1982 -0.6667 -0.2641 0.3715 6.6482
Random effects:
Groups Name Variance Std.Dev.
Avaliador:Foliolo:Trifolio:Planta (Intercept) 3.289e-09 5.735e-05
Foliolo:Trifolio:Planta (Intercept) 1.696e-08 1.302e-04
Trifolio:Planta (Intercept) 1.142e-01 3.380e-01
Planta (Intercept) 1.182e-08 1.087e-04
Residual 6.682e-01 8.175e-01
Number of obs: 660, groups:
Avaliador:Foliolo:Trifolio:Planta, 60; Foliolo:Trifolio:Planta, 30; Trifolio:Planta, 10; Planta, 5
Fixed effects:
Estimate Std. Error t value Pr(>|z|)
(Intercept) 4.42229 0.16286 27.153 < 2e-16 ***
TratamentoIsolado 1 -0.59518 0.13974 -4.259 2.05e-05 ***
TratamentoIsolado 2 -0.16528 0.14568 -1.135 0.25657
TratamentoIsolado 3 0.02049 0.14195 0.144 0.88525
TratamentoIsolado 4 -0.29423 0.14399 -2.043 0.04101 *
TratamentoIsolado 5 0.13360 0.14225 0.939 0.34763
TratamentoIsolado 6 0.83154 0.14096 5.899 3.65e-09 ***
TratamentoIsolado 7 -0.41822 0.14013 -2.985 0.00284 **
TratamentoProduto 1 -0.71443 0.14133 -5.055 4.30e-07 ***
TratamentoProduto 2 -0.31449 0.13967 -2.252 0.02434 *
TratamentoProduto 3 -0.58610 0.14056 -4.170 3.05e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) TrtmI1 TrtmI2 TrtmI3 TrtmI4 TrtmI5 TrtmI6 TrtmI7 TrtmP1
TrtmntIsld1 -0.428
TrtmntIsld2 -0.429 0.486
TrtmntIsld3 -0.428 0.495 0.492
TrtmntIsld4 -0.419 0.500 0.485 0.489
TrtmntIsld5 -0.430 0.492 0.509 0.500 0.470
TrtmntIsld6 -0.425 0.485 0.486 0.479 0.472 0.483
TrtmntIsld7 -0.429 0.496 0.488 0.495 0.475 0.506 0.488
TrtmntPrdt1 -0.417 0.479 0.465 0.466 0.442 0.474 0.496 0.487
TrtmntPrdt2 -0.431 0.498 0.493 0.499 0.491 0.495 0.499 0.497 0.486
TrtmntPrdt3 -0.431 0.494 0.500 0.495 0.471 0.506 0.493 0.504 0.488
TrtmP2
TrtmntIsld1
TrtmntIsld2
TrtmntIsld3
TrtmntIsld4
TrtmntIsld5
TrtmntIsld6
TrtmntIsld7
TrtmntPrdt1
TrtmntPrdt2
TrtmntPrdt3 0.497
optimizer (Nelder_Mead) convergence code: 0 (OK)
boundary (singular) fit: see help('isSingular')res_sim_35 <- simulateResiduals(modelo_glmm_35)
plot(res_sim_35)
# -----------------------------
# 📊 7. Médias ajustadas e letras de significância
# -----------------------------
medias_35 <- emmeans(modelo_glmm_35, ~ Tratamento, type = "response")
letras_35 <- cld(medias_35, Letters = letters, adjust = "tukey")
letras_35$.group <- gsub(" ", "", letras_35$.group)
# Renomear tratamentos para gráfico
letras_35$Tratamento <- letras_35$Tratamento %>%
str_replace("(?i)isola[dt]o\\s*", "Iso. ") %>%
str_replace("(?i)produto\\s*", "Prod. ") %>%
str_replace("(?i)controle", "Cont.")
# -----------------------------
# 📦 8. Organizar para gráfico
# -----------------------------
letras_df_35 <- letras_35[, c("Tratamento", "response", "SE", ".group")]
# Reordenar fatores para o gráfico
ordem_35 <- letras_df_35$Tratamento[order(letras_df_35$response)]
letras_df_35$Tratamento <- factor(letras_df_35$Tratamento, levels = ordem_35)
# -----------------------------
# 🎨 9. Gráfico final
# -----------------------------
ggplot(letras_df_35, aes(x = Tratamento, y = response)) +
geom_col(fill = "#BC8F8F", width = 0.7) +
geom_errorbar(aes(ymin = response - SE, ymax = response + SE), width = 0.2) +
geom_text(aes(label = .group), vjust = -0.5, fontface = "bold", size = 5) +
labs(
title = "AACPD dos tratamentos (até 35 dias)",
x = "Tratamentos",
y = "AACPD"
) +
theme_minimal(base_size = 14) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))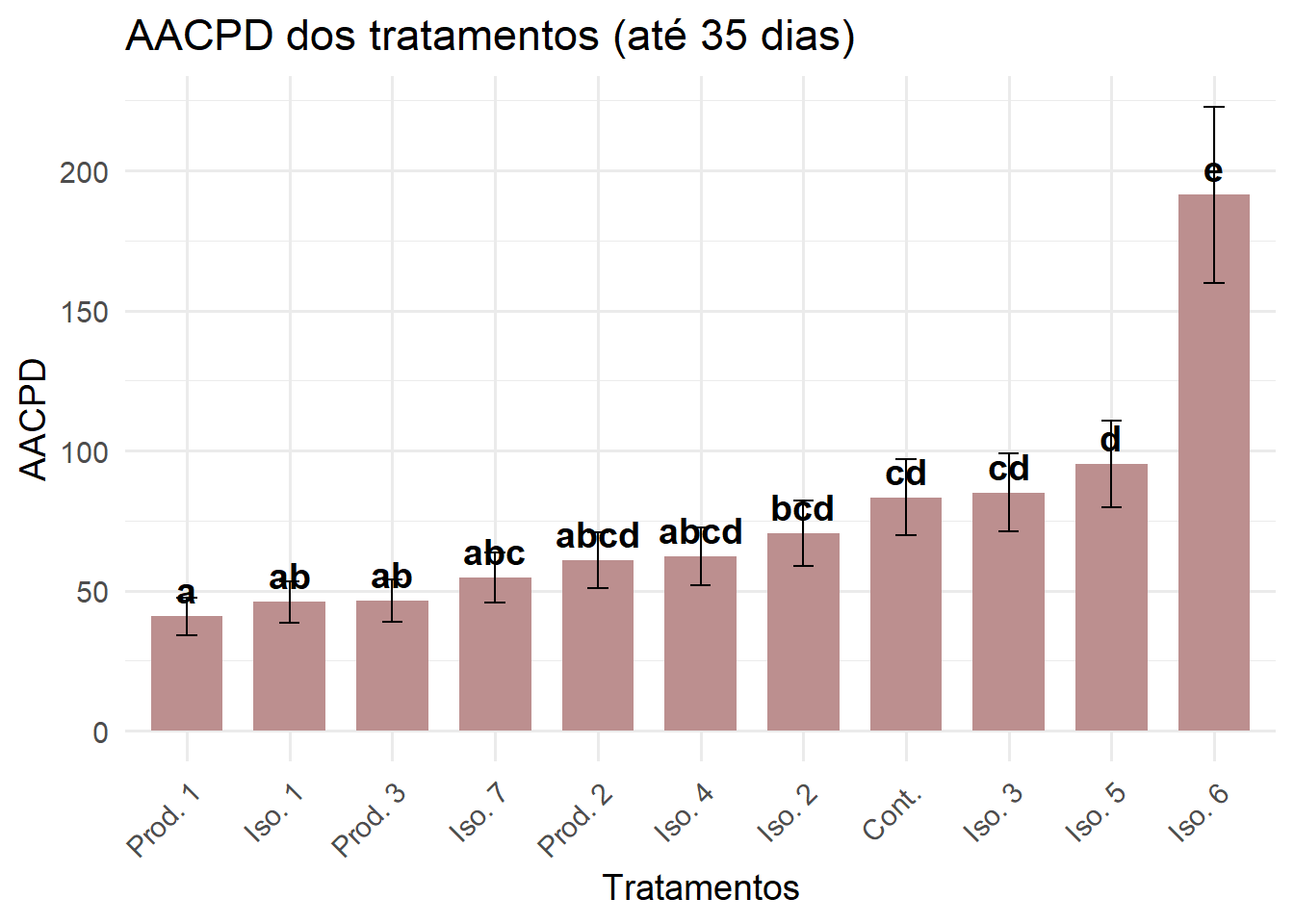
Com base nos resultados obtidos, foi possível verificar que os diferentes tratamentos avaliados influenciaram significativamente a progressão da ferrugem asiática da soja, conforme evidenciado pelas análises de AACPD sob modelos mistos e modelos generalizados com distribuição Gamma. O uso de modelos de efeitos mistos foi essencial para considerar a estrutura hierárquica dos dados e garantir estimativas robustas, controlando a variação associada às plantas, folíolos e avaliadores. Os tratamentos foram comparados por meio de médias ajustadas e agrupamentos estatísticos, permitindo identificar quais estratégias de manejo se destacaram no controle da doença ao longo do tempo.